Short Note On Database, Stack And Queues, Linked List, Trees, Searching And Sorting, Tables And Graphs And Introduction About CAD
DATABASE
In computer science, a data structure is the
organization and implementation of values and information. In simple words data structure is the way of
organizing data in efficient manner. Data structures are different from
abstract data types in the way they are used. Data structures are the
implementations of abstract data types in a concrete and physical setting.

They
do this by using algorithms. This can be seen in the relationship between
the list (abstract data type) and the linked list (data structure). A list contains a sequence of values or bits of
information. A linked list also has a “pointer” or “reference” between each
node of information that points to the next item and the previous one. This
allows one to go forwards or backwards in the list. Furthermore, data
structures are often optimized for certain operations. Finding the best data
structure when solving a problem is an important part of programming. Data structure is a systematic way to store
data
Abstract
data structures
In computer science, an abstract data type (ADT) is a
mathematical model for data types where a data type is defined by its behavior
(semantics) from the point of view of a user of the data, specifically in terms
of possible values, possible operations on data of this type, and the behavior
of these operations. This contrasts with data structures, which are concrete
representations of data, and are the point of view of an implementer, not a
user.
Formally, an ADT may be defined as a "class of objects
whose logical behavior is defined by a set of values and a set of operations";
this is analogous to an algebraic structure in mathematics. What is meant by
"behavior" varies by author, with the two main types of formal
specifications for behavior being axiomatic (algebraic) specification and an
abstract model; these correspond to axiomatic semantics and operational
semantics of an abstract machine, respectively. Some authors also include the
computational complexity ("cost"), both in terms of time (for
computing operations) and space (for representing values).[2]
The reason we use abstract structures is because they
efficiently use memory based on the design of the data
stored in them. With very large amounts of data or very frequently changing
data, the data structure can make a huge difference in the efficiency (run
time) of your computer program.
In more common language, an abstract data structure is just
some arrangement of data that we've built into an orderly arrangement.
DAA - Analysis of Algorithms
In theoretical analysis of algorithms, it is common to estimate
their complexity in the asymptotic sense, i.e., to estimate the complexity
function for arbitrarily large input. The term "analysis of
algorithms" was coined by Donald Knuth.
Algorithm analysis is an important part of computational
complexity theory, which provides theoretical estimation for the required
resources of an algorithm to solve a specific computational problem. Most
algorithms are designed to work with inputs of arbitrary length. Analysis of
algorithms is the determination of the amount of time and space resources
required to execute it.
Usually, the efficiency or running time of an algorithm is stated
as a function relating the input length to the number of steps, known as time
complexity, or volume of memory, known as space complexity.
Concept Of List
In computer science, a list or sequence is
an abstract data type that represents a countable number of
ordered values, where the same value may occur more than once. An instance of
a list is a computer representation of the mathematical concept
of a finite sequence; the (potentially) infinite analog of a list is a stream.[1]:§3.5 Lists are a basic example of containers, as they contain other values. If the same value occurs
multiple times, each occurrence is considered a distinct item.
{kind=link}
A singly linked list structure, implementing a
list with 3 integer elements.
The name list is also used for several
concrete data structures that can be used to implement abstract
lists, especially linked lists.
Many programming languages provide support for list data
types, and have special syntax and semantics for lists and list operations.
A list can often be constructed by writing the items in sequence, separated
by commas, semicolons,
and/or spaces, within a pair of delimiters such as parentheses '()', brackets '[]', braces '{}', or angle brackets '<>'. Some languages may allow list types to
be indexed or sliced like array types, in which case the data type is more
accurately described as an array. In object-oriented programming languages, lists are usually provided as instances of subclasses of a generic "list" class, and
traversed via separate iterators. List data types are often implemented
using array data structures or linked lists of some sort, but
other data structures may be more appropriate for some
applications. In some contexts, such as in Lisp programming, the term list may refer specifically to a
linked list rather than an array.
In type theory and functional programming, abstract lists are usually defined inductively by two operations: nil that
yields the empty list, and cons, which adds an item at the
beginning of a list.[2]
Stacks and
Queues
An array is a random
access data structure, where each element can be accessed directly and
in constant time. A typical illustration of random access is a book - each page
of the book can be open independently of others. Random access is critical to
many algorithms, for example binary search.A linked list is a sequential access data structure, where each element can be accesed only in particular order. A typical illustration of sequential access is a roll of paper or tape - all prior material must be unrolled in order to get to data you want.
In this note we consider a subcase of sequential data structures, so-called limited access data sturctures.
Stacks
|
A stack is a container of objects that are inserted and
removed according to the last-in first-out (LIFO) principle. In the pushdown
stacks only two operations are allowed: push the item into
the stack, and pop the item out of the stack. A stack is a
limited access data structure - elements can be added and removed from the
stack only at the top. push adds an item to the top of the
stack, pop removes the item from the top. A helpful analogy
is to think of a stack of books;
you can remove only the top book, also you
can add a new book on the top.
A stack is a recursive data structure. Here is a
structural definition of a Stack:
a stack is either empty or
it consistes of a top and the rest which is a stack; |
|
Applications
- The simplest application of a stack is to reverse
a word. You push a given word to stack - letter by letter - and then pop
letters from the stack.
- Another application is an "undo"
mechanism in text editors; this operation is accomplished by keeping all
text changes in a stack.
|
|
Backtracking. This is a process when you need to
access the most recent data element in a series of elements. Think of a
labyrinth or maze - how do you find a way from an entrance to an exit?
Once you reach a dead end, you must backtrack. But backtrack to where? to
the previous choice point. Therefore, at each choice point you store on a
stack all possible choices. Then backtracking simply means popping a next
choice from the stack. |
- Language processing:
- space for parameters and local variables is
created internally using a stack.
- compiler's syntax check for matching braces is
implemented by using stack.
- support for recursion
Implementation
In the standard library of classes, the data type stack is
an adapter class,
meaning that a stack is built on top of other data structures. The underlying
structure for a stack could be an array, a vector, an ArrayList, a linked list,
or any other collection. Regardless of the type of the underlying data
structure, a Stack must implement the same functionality. This is achieved by
providing a unique interface:
public interface StackInterface<AnyType>
{
public void push(AnyType e);
public AnyType pop();
public AnyType peek();
public boolean isEmpty();
}
The following picture demonstrates the idea of
implementation by composition.
Array-based
implementation
|
|
In an array-based implementation we maintain the following
fields: an array A of a default size (≥ 1), the variable top that
refers to the top element in the stack and the capacity that
refers to the array size. The variable top changes from -1
to
In a fixed-size stack abstraction, the capacity stays unchanged, therefore
when top reaches capacity, the stack object
throws an exception. See ArrayStack.java for
a complete implementation of the stack class.capacity - 1. We
say that a stack is empty when top
= -1, and the stack is full when top = capacity-1.In a dynamic stack abstraction when top reaches capacity, we double up the stack size. |
Linked
List-based implementation
|
Linked List-based implementation provides the best (from
the efficiency point of view) dynamic stack implementation.
See ListStack.java for
a complete implementation of the stack class. |
|
Queues
|
A queue is a container of objects (a linear collection)
that are inserted and removed according to the first-in first-out (FIFO)
principle. An excellent example of a queue is a line of students in the food
court of the UC. New additions to a line made to the back of the queue, while
removal (or serving) happens in the front. In the queue only two operations
are allowed enqueue and dequeue. Enqueue means
to insert an item into the back of the queue, dequeue means removing the
front item. The picture demonstrates the FIFO access.
The difference between stacks and queues is in removing. In a stack we
remove the item the most recently added; in a queue, we remove the item the
least recently added. |
|
Implementation
In the standard library of classes, the data type queue is an adapter class,
meaning that a queue is built on top of other data structures. The underlying
structure for a queue could be an array, a Vector, an ArrayList, a LinkedList,
or any other collection. Regardless of the type of the underlying data
structure, a queue must implement the same functionality. This is achieved by
providing a unique interface.
interface QueueInterface‹AnyType>
{
public boolean isEmpty();
public AnyType getFront();
public AnyType dequeue();
public void enqueue(AnyType e);
public void clear();
}
Each of the above basic
operations must run at constant time O(1). The following picture demonstrates
the idea of implementation by composition.
Circular Queue
Given an array A of a default size (≥ 1) with two
references back and front, originally set to -1
and 0 respectively. Each time we insert (enqueue) a new item, we increase the
back index; when we remove (dequeue) an item - we increase the front index.
Here is a picture that illustrates the model after a few steps:
As you see from the picture, the queue logically moves in the
array from left to right. After several moves back reaches
the end, leaving no space for adding new elements
The circular queue implementation is done by using the modulo operator (denoted %), which is computed by taking the remainder of division (for example, 8%5 is 3). By using the modulo operator, we can view the queue as a circular array, where the "wrapped around" can be simulated as "back % array_size". In addition to the back and front indexes, we maintain another index: cur - for counting the number of elements in a queue. Having this index simplifies a logic of implementation.
See ArrayQueue.java for a complete implementation of a circular queue.
Applications
The simplest two search
techniques are known as Depth-First Search(DFS) and Breadth-First Search (BFS).
These two searches are described by looking at how the search tree
(representing all the possible paths from the start) will be traversed.
Deapth-First Search with a Stack
In depth-first search we go down
a path until we get to a dead end; then we backtrack or back
up (by popping a stack) to get an alternative path.- Create a stack
- Create a new choice point
- Push the choice point onto the stack
- while (not found and stack is not empty)
- Pop the stack
- Find all possible choices after the last one
tried
- Push these choices onto the stack
- Return
Breadth-First Search with a Queue
In breadth-first search we
explore all the nearest possibilities by finding all possible successors and
enqueue them to a queue.- Create a queue
- Create a new choice point
- Enqueue the choice point onto the queue
- while (not found and queue is not empty)
- Dequeue the queue
- Find all possible choices after the last one
tried
- Enqueue these choices onto the queue
- Return
Arithmetic Expression Evaluation
An important application of stacks is in parsing. For
example, a compiler must parse arithmetic expressions written using infix
notation:
1 + ((2 + 3) * 4 + 5)*6
We break the problem of parsing infix expressions into two
stages. First, we convert from infix to a different representation called
postfix. Then we parse the postfix expression, which is a somewhat easier
problem than directly parsing infix.
Converting from Infix to
Postfix. Typically,
we deal with expressions in infix notation2 + 5
where the operators (e.g. +, *) are written between the
operands (e.q, 2 and 5). Writing the operators after the operands gives a
postfix expression 2 and 5 are called operands, and the '+' is operator. The
above arithmetic expression is called infix, since the operator is in between
operands. The expression
2 5 +
Writing the operators before the operands gives a prefix
expression
+2 5
Suppose you want to compute the cost of your shopping trip.
To do so, you add a list of numbers and multiply them by the local sales tax
(7.25%):
70 + 150 * 1.0725
Depending on the calculator, the answer would be either
235.95 or 230.875. To avoid this confusion we shall use a postfix notation
70 150 + 1.0725 *
Postfix has the nice property that parentheses are
unnecessary.
Now, we describe how to convert
from infix to postfix.
1.
Read
in the tokens one at a time
2.
If a
token is an integer, write it into the output
3.
If a
token is an operator, push it to the stack, if the stack is empty. If the stack
is not empty, you pop entries with higher or equal priority and only then you
push that token to the stack.
4.
If a
token is a left parentheses '(', push it to the stack
5.
If a
token is a right parentheses ')', you pop entries until you meet '('.
6.
When
you finish reading the string, you pop up all tokens which are left there.
7.
Arithmetic
precedence is in increasing order: '+', '-', '*', '/';
Example.
Suppose we have an infix expression:
2+(4+3*2+1)/3. We read the string by
characters.'2' - send to the output.
'+' - push on the stack.
'(' - push on the stack.
'4' - send to the output.
'+' - push on the stack.
'3' - send to the output.
'*' - push on the stack.
'2' - send to the output.
Evaluating a Postfix
Expression. We
describe how to parse and evaluate a postfix expression.
1.
We
read the tokens in one at a time.
2.
If it
is an integer, push it on the stack
3.
If it
is a binary operator, pop the top two elements from the stack, apply the
operator, and push the result back on the stack.
Consider
the following postfix expression
5 9 3 + 4 2 * * 7 + *
Here is a chain of operations
Stack Operations Output
--------------------------------------
push(5); 5
push(9); 5 9
push(3); 5 9 3
push(pop() + pop()) 5 12
push(4); 5 12 4
push(2); 5 12 4 2
push(pop() * pop()) 5 12 8
push(pop() * pop()) 5 96
push(7) 5 96 7
push(pop() + pop()) 5 103
push(pop() * pop()) 515
Note, that division is not a commutative operation, so 2/3 is
not the same as 3/2.
LINKED LIST
The linked list or one way list is a linear set of data elements
which is also termed as nodes. Here, the linear order is specified using
pointers.
Each node is separated into two different parts:
·
The first part holds the information of the element or node
·
The second piece contains the address of the next node (link /
next-pointer field) in this structure list.
Linked lists can be measured as a form of high-level standpoint as
being a series of nodes where each node has at least one single pointer to the
next connected node, and in the case of the last node, a null pointer is used
for representing that there will be no further nodes in the linked list. In the
data structure, you will be implementing the linked lists which always maintain
head and tail pointers for inserting values at either the head or tail of the
list is a constant time operation. Randomly inserting of values is excluded
using this concept and will follow a linear operation. As such, linked lists in
data structure have some characteristics which are mentioned below:
·
Insertion is O(1)
·
Deletion is O(n)
·
Searching is O(n)
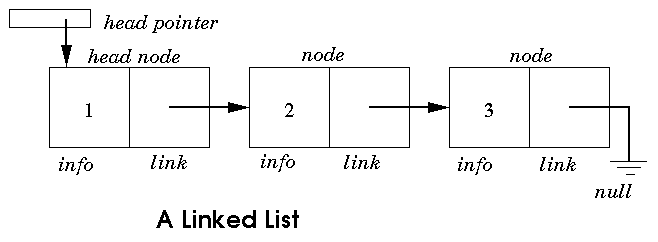
Linked lists have a few key points that usually make them very
efficient for implementing. These are:
·
the list is dynamic and hence can be resized based on the
requirement
·
Secondly, the insertion is O(1).
Table of Contents
Singly Linked List
Singly linked lists are one of the most primitive data structures
you will learn in this tutorial. Here each node makes up a singly linked list
and consists of a value and a reference to the next node (if any) in the list.
Insertion of Values in Linked List
In general, when people talk about insertion concerning linked
lists of any form, they implicitly refer to the adding of a node to the tail of
the list.
Adding a node to a singly linked list has only two cases:
·
head = fi, in which case the node we are adding is now both the
head and tail of the list; or
·
we simply need to append our node onto the end of the list
updating the tail reference appropriately
Algorithm for inserting values to Linked List
·
also Add(value)
·
Pre: value is the value to be added to the list
·
Post: value has been placed at the tail of the list
·
n <- node(value)
·
if head = fi
·
head <- n
·
tail<- n
·
else
·
Next <- n
·
tail <- n
·
end if
·
end Add
Searching in Linked Lists
Searching a linked list is straightforward: we simply traverse the
list checking the value we are looking for with the value of each node in the
linked list.
·
also Contains(head, value)
·
Pre: the head is the head node in the list
·
value is the value to search for
·
Post: the item is either in the linked list, true; otherwise false
·
n <- head
·
While n 6= fi and n.Value 6= value
·
n <- n.Next
·
end while
·
if n = fi
·
return false
·
end if
·
return true
·
end Contains
Deletion in Linked Lists
Deleting a node from a linked list is straight-forward, but there
are some cases that you need to account for:
·
the list is empty; or
·
the node to remove is the only node in the linked list; or
·
we are removing the head node; or
·
we are removing the tail node; or
·
the node to remove is somewhere in between the head and tail; or
·
the item to remove doesn't exist in the linked list
Algorithm for Deletion
·
algorithm Remove(head, value)
·
Pre: the head is the head node in the list
·
value is the value to remove from the list
·
Post: value is removed from the list, true; otherwise false
·
if head = fi
·
return false
·
end if
·
n <- head
·
If n.Value = value
·
if the head = tail
·
head <- fi
·
tail <- fi
·
else
·
HHead <- head.Next
·
end if
·
return true
·
end if
·
while n.Next 6= fi and n.Next.Value 6= value
·
n <- n.Next
·
end while
·
if n.Next 6= fi
·
if n.Next = tail
·
tail <- n
·
end if
·
// this is only case 5 if the conditional on line 25 was false
·
Next <- n.Next.Next
·
return true
·
end if
·
return false
·
end Remove
TREES
There are two ways to represent binary trees. These are:
·
Using arrays
·
Using Linked lists
Table of Contents

The Non-Linear Data structure
The data structures that you have learned so far were merely
linear - strings, arrays, lists, stacks, and queues. One of the most important
nonlinear data structure is the tree. Trees are mainly used to represent data
containing the hierarchical relationship between elements, example: records,
family trees, and table of contents. A tree may be defined as a finite set 'T'
of one or more nodes such that there is a node designated as the root of the
tree and the other nodes are divided into n>=0 disjoint sets T1, T2, T3, T4 …. Tn are called the
subtrees or children of the root.
What is a Binary Tree?
A binary tree is a special type of tree in which every node or
vertex has either no child node or one child node or two child nodes. A binary
tree is an important class of a tree data structure in which a node can have at
most two children.
Child node in a binary tree on the left is termed as 'left child
node' and node in the right is termed as the 'right child node.'
In the figure mentioned below, the root node 8 has two children 3
and 10; then this two child node again acts as a parent node for 1 and 6 for
left parent node 3 and 14 for right parent node 10. Similarly, 6 and 14 has a
child node.
A binary tree may also be defined as follows:
·
A binary tree is either an empty tree
·
Or a binary tree consists of a node called the root node, a left
subtree and a right subtree, both of which will act as a binary tree once again
Applications of Binary Tree
Binary trees are used to represent a nonlinear data structure.
There are various forms of Binary trees. Binary trees play a vital role in a
software application. One of the most important applications of the Binary tree
is in the searching algorithm.
A general tree is defined as a
nonempty finite set T of elements called nodes such that:
·
The tree contains the root element
·
The remaining elements of the tree form an ordered collection of
zeros and more disjoint trees T1, T2, T3, T4 …. Tn which are called subtrees.
Types of Binary Trees are
·
A full binary tree which is also called
as proper binary tree or 2-tree is a tree in which all the node other than the
leaves has exact two children.
·
A complete binary tree is a binary tree
in which at every level, except possibly the last, has to be filled and all
nodes are as far left as possible.
·
A binary tree can be converted into an extended binary tree by
adding new nodes to its leaf nodes and to the nodes that have only one child.
These new nodes are added in such a way that all the nodes in the resultant
tree have either zero or two children. It is also called 2 - tree.
·
The threaded Binary tree is the tree which is
represented using pointers the empty subtrees are set to NULL, i.e. 'left'
pointer of the node whose left child is empty subtree is normally set to NULL.
These large numbers of pointer sets are used in different ways.
SORTING
Sorting refers to the operation or technique of arranging and
rearranging sets of data in some specific order. A collection of records called
a list where every record has one or more fields. The fields which contain a
unique value for each record is termed as the key field. For example,
a phone number directory can be thought of as a list where each record has
three fields - 'name' of the person, 'address' of that person, and their 'phone
numbers'. Being unique phone number can work as a key to locate any record in
the list.

Sorting is the operation performed to arrange the records of a
table or list in some order according to some specific ordering criterion.
Sorting is performed according to some key value of each record.
The records are either sorted either numerically or
alphanumerically. The records are then arranged in ascending or descending
order depending on the numerical value of the key. Here is an example, where
the sorting of a lists of marks obtained by a student in any particular subject
of a class.
Categories of Sorting
The techniques of sorting can be divided into two categories.
These are:
·
Internal Sorting
·
External Sorting
Internal Sorting: If all the data that is to
be sorted can be adjusted at a time in the main memory, the internal sorting
method is being performed.
External Sorting: When the data that is to
be sorted cannot be accommodated in the memory at the same time and some has to
be kept in auxiliary memory such as hard disk, floppy disk, magnetic tapes etc,
then external sorting methods are performed.
The Complexity of Sorting Algorithms
The complexity of sorting algorithm calculates the running time of
a function in which 'n' number of items are to be sorted. The choice for which
sorting method is suitable for a problem depends on several dependency
configurations for different problems. The most noteworthy of these
considerations are:
·
The length of time spent by the programmer in programming a
specific sorting program
·
Amount of machine time necessary for running the program
·
The amount of memory necessary for running the program
The Efficiency of Sorting Techniques
To get the amount of time required to sort an array of 'n'
elements by a particular method, the normal approach is to analyze the method
to find the number of comparisons (or exchanges) required by it. Most of the
sorting techniques are data sensitive, and so the metrics for them depends on
the order in which they appear in an input array.
Various sorting techniques are analyzed in various cases and named
these cases as follows:
·
Best case
·
Worst case
·
Average case
Hence, the result of these cases is often a formula giving the
average time required for a particular sort of size 'n.' Most of the sort
methods have time requirements that range from O(nlog n) to O(n2).
Types of Sorting Techniques
·
Insertion Sort
·
Quick Sort
·
Heap Sort
SEARCHING
Searching is an operation or a technique that helps finds the
place of a given element or value in the list. Any search is said to be
successful or unsuccessful depending upon whether the element that is being
searched is found or not. Some of the standard searching technique that is
being followed in the data structure is listed below:

·
Linear Search or Sequential Search
·
Binary Search
What is Linear Search?
This is the simplest method for searching. In this technique of
searching, the element to be found in searching the elements to be found is
searched sequentially in the list. This method can be performed on a sorted or
an unsorted list (usually arrays). In case of a sorted list searching starts
from 0th element and continues until the element is found from the
list or the element whose value is greater than (assuming the list is sorted in
ascending order), the value being searched is reached.
As against this, searching in case of unsorted list also begins
from the 0th element and continues until the element or the end of the
list is reached.
Example:
The list given below is the list of elements in an unsorted array. The array contains ten elements. Suppose the element to be searched is '46', so 46 is compared with all the elements starting from the 0th element, and the searching process ends where 46 is found, or the list ends.
The list given below is the list of elements in an unsorted array. The array contains ten elements. Suppose the element to be searched is '46', so 46 is compared with all the elements starting from the 0th element, and the searching process ends where 46 is found, or the list ends.
The performance of the linear search can be measured by counting
the comparisons done to find out an element. The number of comparison is 0(n).
Graph
A graph is a pictorial representation of a set of objects where
some pairs of objects are connected by links. The interconnected objects are
represented by points termed as vertices, and the links that
connect the vertices are called edges.
Formally, a graph is a pair of sets (V, E),
where V is the set of vertices and E is the
set of edges, connecting the pairs of vertices. Take a look at the following
graph −
In the above graph,
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
Graph
Data Structure
Mathematical graphs can be represented in data structure. We can
represent a graph using an array of vertices and a two-dimensional array of
edges. Before we proceed further, let's familiarize ourselves with some
important terms −
·
Vertex − Each node of the graph is
represented as a vertex. In the following example, the labeled circle
represents vertices. Thus, A to G are vertices. We can represent them using an
array as shown in the following image. Here A can be identified by index 0. B
can be identified using index 1 and so on.
·
Edge − Edge represents a path
between two vertices or a line between two vertices. In the following example,
the lines from A to B, B to C, and so on represents edges. We can use a
two-dimensional array to represent an array as shown in the following image.
Here AB can be represented as 1 at row 0, column 1, BC as 1 at row 1, column 2
and so on, keeping other combinations as 0.
·
Adjacency − Two node or vertices
are adjacent if they are connected to each other through an edge. In the
following example, B is adjacent to A, C is adjacent to B, and so on.
·
Path − Path represents a sequence
of edges between the two vertices. In the following example, ABCD represents a
path from A to D.
Basic
Operations
Following are basic primary operations of a Graph −
·
Add Vertex − Adds a vertex to the
graph.
·
Add Edge − Adds an edge between the
two vertices of the graph.
·
Display Vertex −
Displays a vertex of the graph.
Hash Table
Hash Table is a data structure which stores data in an associative
manner. In a hash table, data is stored in an array format, where each data
value has its own unique index value. Access of data becomes very fast if we
know the index of the desired data.
Thus, it becomes a data structure in which insertion and search
operations are very fast irrespective of the size of the data. Hash Table uses
an array as a storage medium and uses hash technique to generate an index where
an element is to be inserted or is to be located from.
Hashing
Hashing is a technique to convert a range of key values into a
range of indexes of an array. We're going to use modulo operator to get a range
of key values. Consider an example of hash table of size 20, and the following
items are to be stored. Item are in the (key,value) format.
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
|
Sr.No.
|
Key
|
Hash
|
Array
Index
|
|
1
|
1
|
1 %
20 = 1
|
1
|
|
2
|
2
|
2 %
20 = 2
|
2
|
|
3
|
42
|
42 %
20 = 2
|
2
|
|
4
|
4
|
4 %
20 = 4
|
4
|
|
5
|
12
|
12 %
20 = 12
|
12
|
|
6
|
14
|
14 %
20 = 14
|
14
|
|
7
|
17
|
17 %
20 = 17
|
17
|
|
8
|
13
|
13 %
20 = 13
|
13
|
|
9
|
37
|
37 %
20 = 17
|
17
|
Linear
Probing
As we can see, it may happen that the hashing technique is used to
create an already used index of the array. In such a case, we can search the
next empty location in the array by looking into the next cell until we find an
empty cell. This technique is called linear probing.
|
Sr.No.
|
Key
|
Hash
|
Array
Index
|
After
Linear Probing, Array Index
|
|
1
|
1
|
1 %
20 = 1
|
1
|
1
|
|
2
|
2
|
2 %
20 = 2
|
2
|
2
|
|
3
|
42
|
42 %
20 = 2
|
2
|
3
|
|
4
|
4
|
4 %
20 = 4
|
4
|
4
|
|
5
|
12
|
12 %
20 = 12
|
12
|
12
|
|
6
|
14
|
14 %
20 = 14
|
14
|
14
|
|
7
|
17
|
17 %
20 = 17
|
17
|
17
|
|
8
|
13
|
13 %
20 = 13
|
13
|
13
|
|
9
|
37
|
37 %
20 = 17
|
17
|
18
|
Basic
Operations
Following are the basic primary operations of a hash table.
·
Search − Searches an element in a
hash table.
·
Insert − inserts an element in a
hash table.
·
delete − Deletes an element from a
hash table.
DataItem
Define a data item having some data and key, based on which the
search is to be conducted in a hash table.
struct DataItem {
int data;
int key;
};
Hash
Method
Define a hashing method to compute the hash code of the key of the
data item.
int hashCode(int key){
return key % SIZE;
}
Search
Operation
Whenever an element is to be searched, compute the hash code of
the key passed and locate the element using that hash code as index in the
array. Use linear probing to get the element ahead if the element is not found
at the computed hash code.
Example
struct DataItem *search(int key) {
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) {
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
Insert
Operation
Whenever an element is to be inserted, compute the hash code of
the key passed and locate the index using that hash code as an index in the
array. Use linear probing for empty location, if an element is found at the
computed hash code.
Example
void insert(int key,int data) {
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty or deleted cell
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
Delete
Operation
Whenever an element is to be deleted, compute the hash code of the
key passed and locate the index using that hash code as an index in the array.
Use linear probing to get the element ahead if an element is not found at the
computed hash code. When found, store a dummy item there to keep the
performance of the hash table intact.
Example
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
Computer-aided
design/Computer Aided Drafting
Computer Aided Drafting (CAD) means using the computer, instead of the
classical tools (pencil, ink, rulers, paper) to create drawings. There are
several advantages to this, for example the drawing can be subdivided in
smaller parts, that can be reused or be worked on by several architects,
updating the drawing is much faster than with hand-made drawings (where you
often needed to redraw the whole drawing), and several tools can help you to
check your drawing for errors. Besides this, computer generally allows you to
work in real-world units, and does the scaling automatically, so your drawing
fits on the printer sheet.
CAD Applications are nowadays complex and very carefully
conceived. Therefore most of them are highly expensive software. Among the most
used worldwide, are Autocad, Archicad, Inventor, Microstation, Vectorworks or Allplan. Almost all engineering and architecture
offices on the planet use one of them, so knowing at least some of them is very
important in the professional world, and usually the most important requirement
on architecture job offerings.
Those applications are generally used to design whole
architecture or engineering projects, often from scratch, and to produce the
printed drawings that will be used to discuss the project with involved people
such as project partners, authorities and clients, and the execution documents
that will be used by the building team to actually build the project. Nowadays,
all of them can be used to make 2-dimensional drawings directly (similarly to
drawing on a sheet of paper), or to build a 3-dimensional model of your
project, from which the software will extract 2D drawings that will be printed
on paper.

Hello guys, your data structure notes are very good and explanation are very easy. I hope, you next post very soon.
ReplyDeleteThanks for ur valuable comment
ReplyDeleteu deserve
Deleteawesome work dear
ReplyDelete